目录
深入剖析Redis慢查询、过期策略与大Key处理秘诀
Redis以其惊人的亚毫秒级响应速度成为现代应用的核心组件,但当它变慢时,整个系统都可能陷入停滞。本文将深入解析Redis性能优化的关键策略,涵盖慢查询根因、过期机制原理和大Key处理技巧。
🔍 一、Redis为什么变慢?九大核心瓶颈解析
- 网络瓶颈
- 跨地域部署导致高延迟
- 大Value传输耗尽带宽(如10MB的String)
- 连接风暴(
maxclients默认为10000)
- 内存管理陷阱
redis# 危险配置示例 maxmemory 0# 未设置内存上限 maxmemory-policy noeviction# 默认拒绝写入
- 内存Swap:访问磁盘比内存慢10万倍
- 内存碎片率>1.5:
INFO memory查看mem_fragmentation_ratio - Key集中过期导致清理延迟
- 命令性能杀手
| 危险命令 | 替代方案 |
|---|---|
| KEYS * | SCAN迭代 |
| HGETALL | HSCAN分片 |
| SMEMBERS | SSCAN分批获取 |
| FLUSHDB/FLUSHALL | 异步删除脚本 |
- 持久化阻塞
bgsavefork阻塞:8GB内存fork耗时约200ms- AOF配置风险:
redisappendfsync always# 每次写入刷盘(性能最差) appendfsync everysec # 默认配置(推荐)
⏳ 二、Redis过期策略精解:两级协同守护内存
Redis采用惰性删除+定期删除双剑合璧:
- 惰性删除(访问时触发)
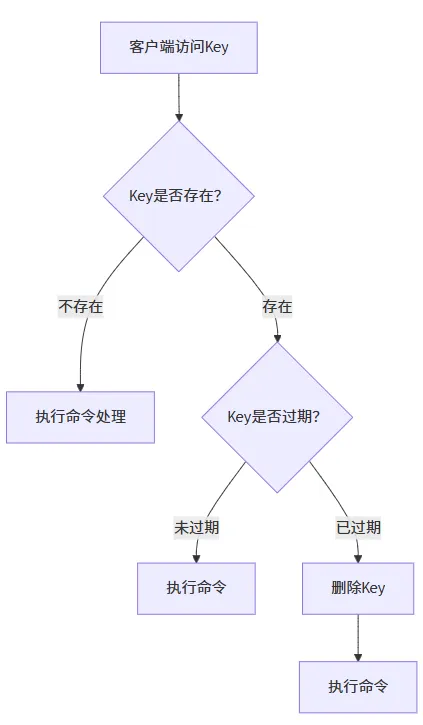
- 定期删除(每秒10次)
- 随机抽查20个带TTL的Key
- 删除所有过期Key
- 当淘汰率>25%时持续抽查
实战配置建议:
redis# 调整清理频率(1-500) hz 20# 适当增加频率应对大量过期Key
三、内存淘汰机制:Redis的最后防线
当maxmemory被触发时,淘汰策略决定生存者:
| 策略 | 特点 | 适用场景 |
|---|---|---|
allkeys-lru | 淘汰最近最少使用的Key | 通用推荐方案 |
allkeys-lfu | 淘汰访问频率最低的Key | 存在长期热点数据 |
volatile-ttl | 淘汰最快过期的Key | 临时数据为主场景 |
noeviction | 拒绝写入(默认!需修改) | 禁止生产环境使用 |
配置示例:
redismaxmemory 16gb maxmemory-policy allkeys-lfu# Redis 4.0+推荐 maxmemory-samples 10# 提高LRU/LFU精度
🔎 四、大Key定位四板斧:精准定位性能杀手
- 官方利器
--bigkeys
bashredis-cli -h 127.0.0.1 --bigkeys
# 输出:Biggest string found 'user:avatar:1001' has 12.5 MB
- 内存分析命令
redisMEMORY USAGE user:profile:1001# 精确获取内存占用
- 离线RDB分析(最安全)
bashrdb -c memory dump.rdb --bytes 102400 > bigkeys.csv
- 渐进式扫描脚本
python# Python扫描大Key示例
for key in r.scan_iter(count=1000):
if r.memory_usage(key) > 100*1024: # >100KB
print(f"大Key: {key.decode()}")
️ 五、大Key处理实战手册
- 数据结构拆分
redis# 原始大Hash → 分片存储 HSET user:1001:profile_base name "张三" HSET user:1001:profile_ext address "北京..."
- 数据压缩技巧
python# 写入压缩数据
r.set("large_json", zlib.compress(json_data))
- 命令优化方案
| 危险操作 | 安全替代 |
|---|---|
| HGETALL | HSCAN + HMGET |
| LRANGE 0 -1 | LTRIM + 分页获取 |
| SMEMBERS | SSCAN分批获取 |
- 自动过期设置
redisEXPIRE large_temp_data 3600# 1小时后自动清理
💎 总结:Redis性能优化三大黄金法则
- 预防优于治疗
- 设置
maxmemory和合理的maxmemory-policy - 为临时数据添加TTL
- 避免使用
O(N)复杂度命令
- 持续监控关键指标
bashwatch -n 1 "redis-cli info memory | grep -E 'used_memory|frag'"
- 定期进行大Key体检
- 生产环境每月执行
redis-cli --bigkeys - 重要服务使用
rdb-tools离线分析
终极建议:将大Key扫描纳入DevOps例行巡检,建立Redis性能基线(如
redis-cli --latency-history),当延迟波动>20%时立即告警。
通过本文的系统性优化方案,您将显著提升Redis性能,构建坚如磐石的基础设施支撑能力!
本文作者:JACK WEI
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录